Artificial intelligence and networking are no longer moving in separate lanes – they’re driving each other forward. AI demands faster, smarter, more predictable networks to operate at scale, while networks are evolving under AI’s influence to become more adaptive, automated, and intelligent.
It’s a powerful feedback loop: AI pushes network design toward ultra-low latency, massive bandwidth, and full programmability; in return, next-generation networks deliver the visibility, control, and agility that make advanced AI possible.
In this article, we’ll walk through how AI is reshaping networking and, conversely, how advanced network topologies and open-source systems like SONiC are enabling AI at scale.
The dual dance: “AI for Networking” vs. “Networking for AI”
Let’s start with the basics. AI and networking influence each other along two key vectors: “AI for Networking” (AIOps) and “Networking for AI”.
On one hand, AI is improving network operations. Traditional networking has long relied on manual configuration, reactive troubleshooting, and a lot of tribal knowledge. AIOps applies machine learning to telemetry to predict failures, correlate events across logs and sensors, and automate remediation. The result is a network that increasingly self-heals, spotting anomalies in real time and, in many cases, using generative AI to propose root causes based on historical patterns.
Intent-based networking (IBN) raises this step further. Rather than micromanaging every switch and router, operators express high-level goals (for example, “ensure low-latency for AI training traffic”) and AI agents translate that intent into policies, monitor KPIs, and keep the system within desired bounds via closed-loop automation powered by NLP (Natural Language Processing) and continuous feedback.
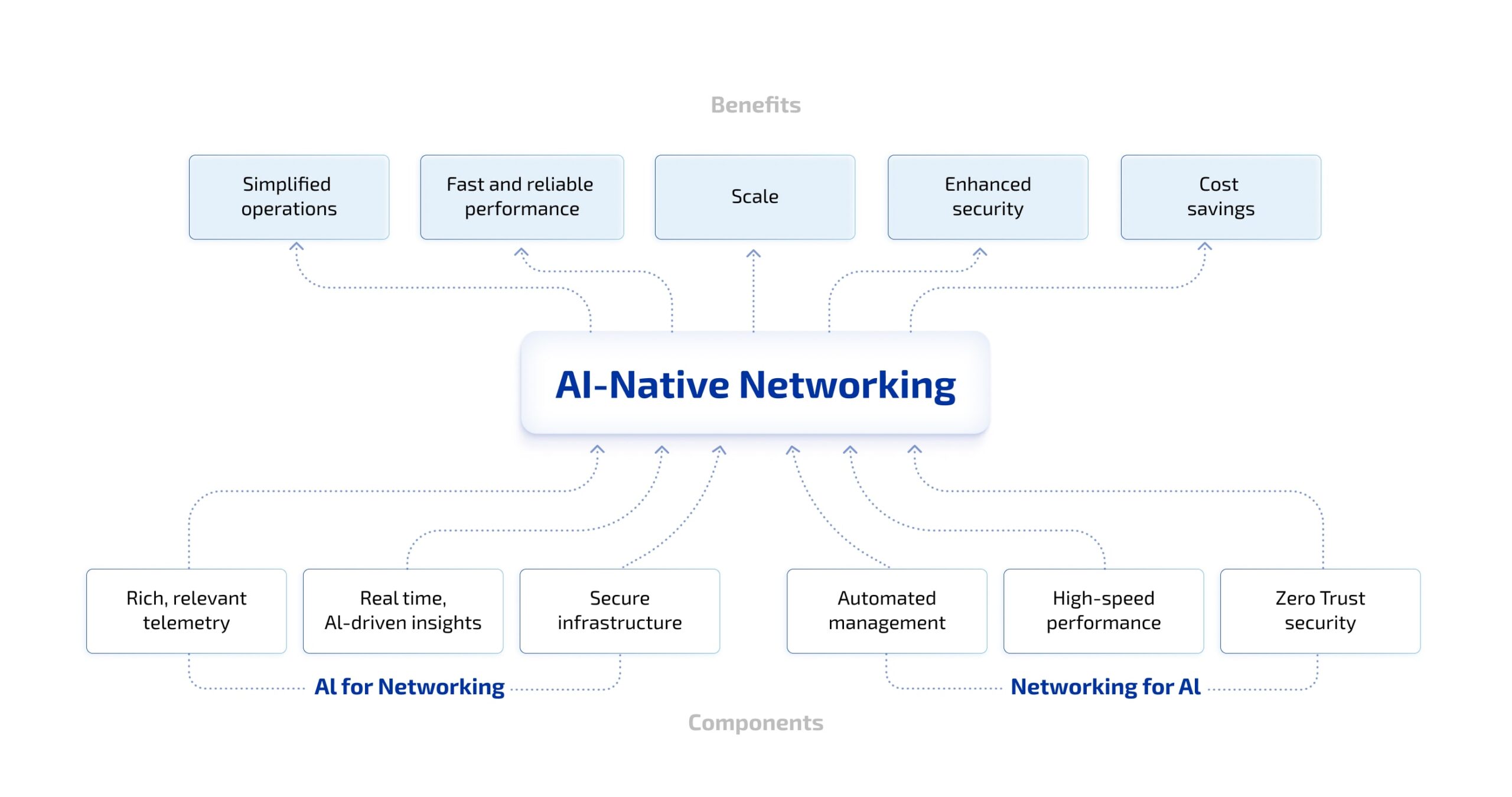
AI-Native Networking Components
Flip the coin: the network is what enables AI. Large-scale AI workloads, especially distributed training across hundreds or thousands of GPUs, generate massive east–west traffic as nodes exchange gradients and parameters. That traffic needs ultra-high bandwidth, sub-microsecond latency, and minimal jitter. If the fabric can’t deliver, job completion time (JCT) balloons and a “gigantic GPU” cluster can feel like a sluggish, underutilized resource.
The magic is that these two vectors amplify each other: more intelligent networks simplify the operational burden for AI, while richer telemetry and assurance let operators push fabrics harder with confidence. But what specific network characteristics make a fabric truly AI-ready? The following chapter translates the dual dance into concrete technical differentiators.
What makes an AI-ready fabric different
A “regular” data-center network and an AI-optimized fabric diverge in a few practical, measurable ways.
- Lossless, predictable transport. Technologies like RDMA (RoCEv2) and careful buffer management are essential to avoid packet loss under heavy incast and microbursts.
- Topology matched to the workload. Large models sometimes benefit from torus-like or rail topologies that reduce hop counts between GPUs; other cases perform best on non-blocking fat-trees. Choose topology based on communication patterns, not convenience.
- Hardware – software co-design. NICs, DPUs, switch ASICs, and collective libraries need joint tuning. In-network compute (INC) and switch-assisted All-Reduce can optimize host CPU overhead and overall network traffic.
- High-frequency telemetry. Telemetry is the network’s nervous system. Treating it as foundational infrastructure unlocks predictive assurance and automation.
These characteristics aren’t theoretical as they translate directly into improved JCT, better utilization, and optimized total cost of ownership (TCO) for AI clusters. And the next step is to convert them into concrete actions your team can take.
A practical checklist for teams building AI fabrics
Our checklist names the concrete steps teams must get right to build reliable, observable, and cost-effective AI fabrics.
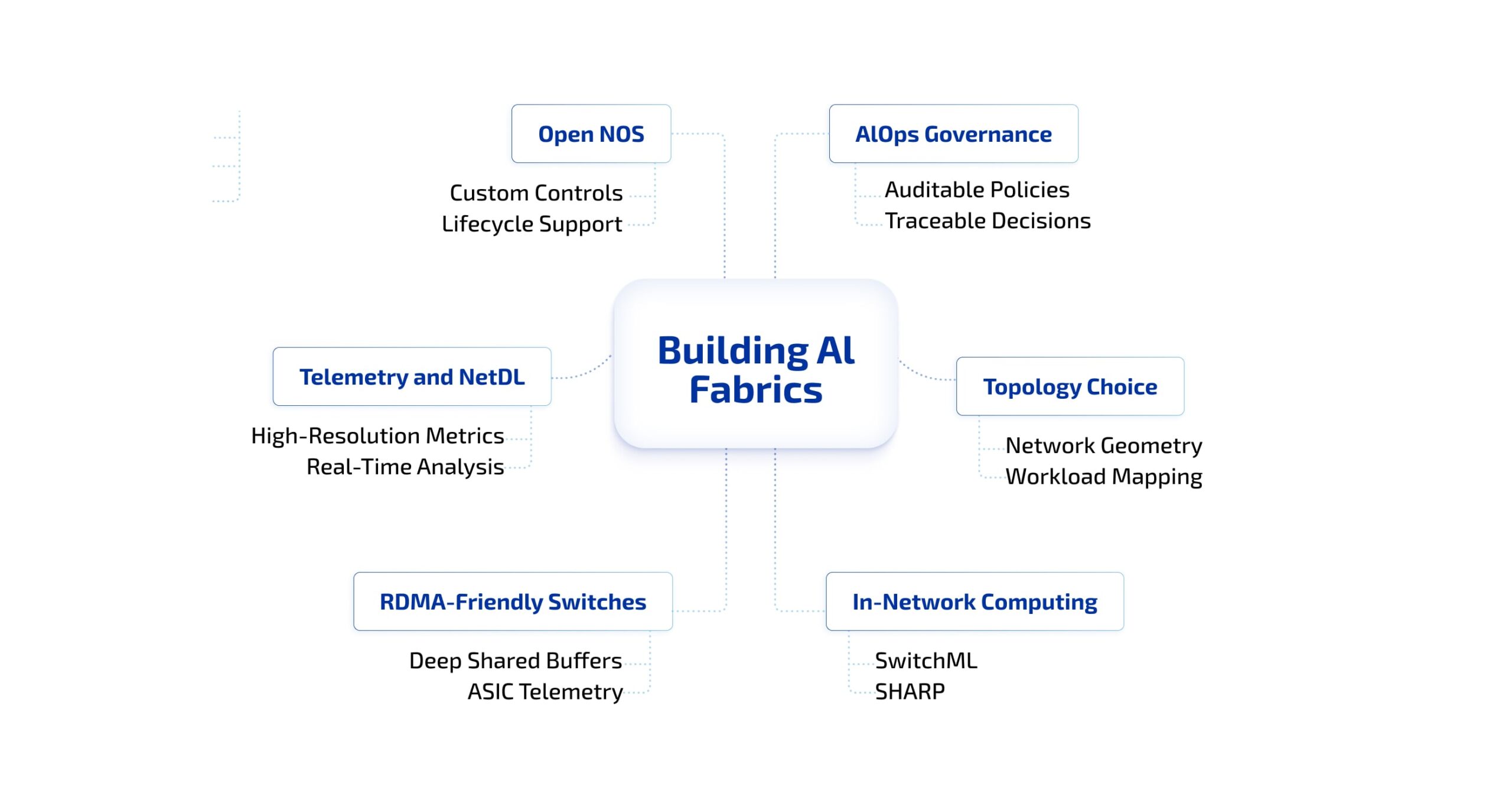
Building AI Fabrics: A Practical Checklist
As the diagram shows, follow these steps:
- High-resolution telemetry + NetDL – capture per-flow metrics, ASIC counters and sampled traces; define retention/sampling up front.
- Topology by workload – design topology for your model’s communication (all-reduce, broadcasts), and prototype with traffic generators.
- RDMA-friendly hardware – require RDMA/ROCE, deep shared buffers, and per-ASIC telemetry in procurement and lab tests.
- In-network offloads – evaluate SwitchML/SHARP for heavy collectives; measure latency/CPU benefits and plan fallbacks.
- Open NOS with hardening – use open NOS for control, but add CI/CD, security hardening, and lifecycle support.
- AIOps governance – log automated actions, attach policy metadata, keep approvals auditable and decisions traceable.
- Cost-aware observability – define telemetry tiers, sampling rules, quotas, and chargeback tracking from day one.
Open NOS is one piece of the AI-networking puzzle. The next chapter explains how SONiC is reinventing itself for AI workloads and what that means for scale, observability, and cost.
Tackling scale: economics and the role of open networking
Scaling AI is expensive and operationally complex. Hyperscalers juggle ever-changing hardware (new GPUs arrive every year) and a mix of accelerators; managing that heterogeneity increases TCO. AI and automation help, but the structural game-changer is open networking: decoupling software from hardware to enable vendor neutrality, customization, and cost control.
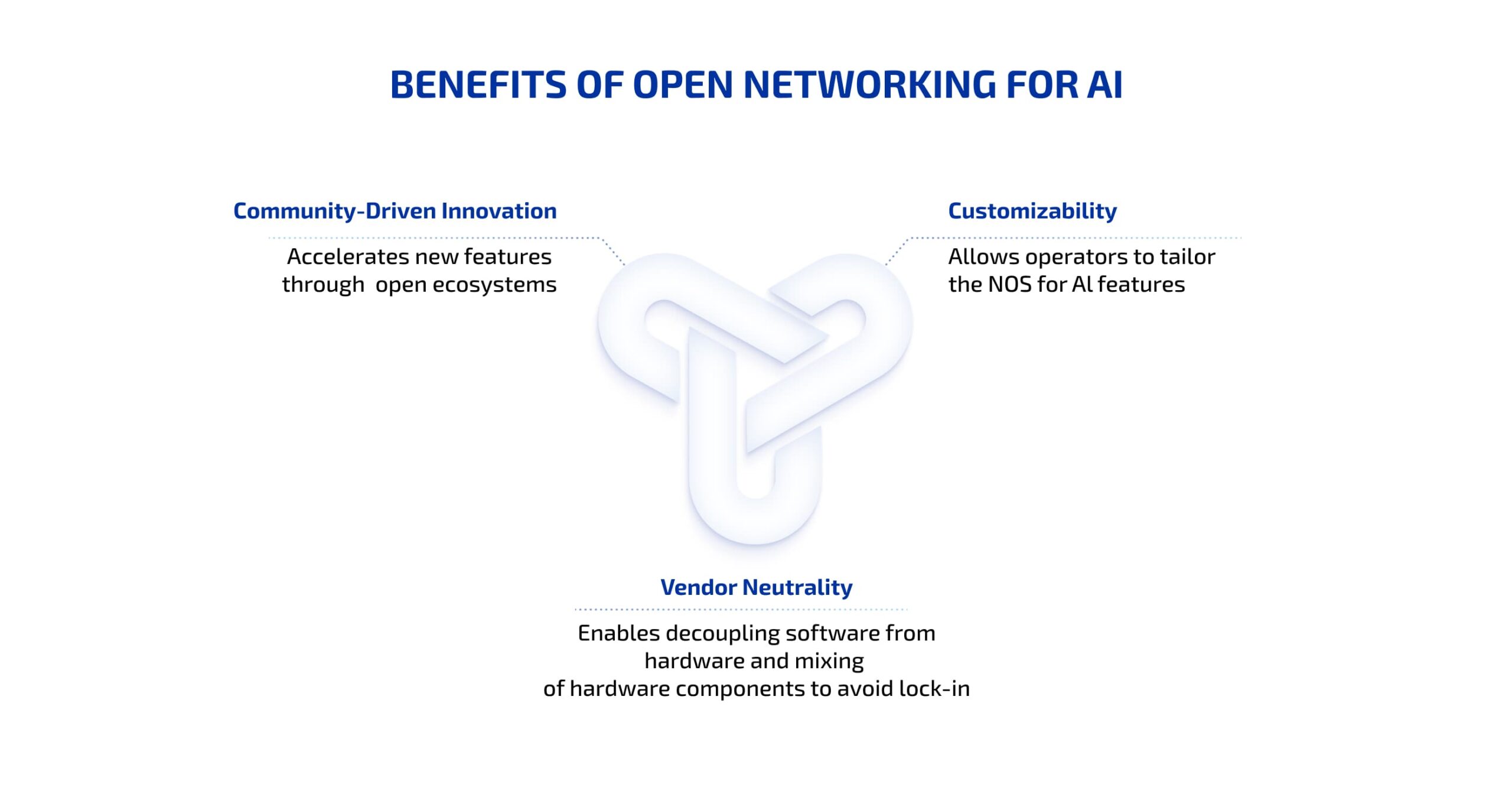
Benefits of Open Networking for AI
SONiC (Software for Open Networking in the Cloud) is an open-source network operating system that has become a leading choice for AI clusters. Built on Linux, SONiC supports RoCE for lossless traffic, advanced QoS primitives like PFC and ECN, and programmability via P4 for in-network functions. It’s designed to be scalable, economical, and flexible, enabling multi-vendor fabrics that avoid lock-in.
SONiC’s fit for AI workloads is practical:
- Support for RoCE to enable efficient GPU-to-GPU data movement and avoid communication bottlenecks.
- QoS and congestion controls (PFC, ECN, ETS, improved hashing) to prioritize critical GPU traffic and reduce packet loss.
- Low-latency features like cut-through switching and scheduling algorithms (SP, DWRR, WRR) to tune performance.
- Advanced telemetry and real-time diagnostics (gRPC/gNMI, Everflow) that integrate with AI-driven tools for anomaly detection and flow analysis.
- P4 programmability through stacks like PINS to add programmable pipelines and SDN interfaces, enabling centralized traffic engineering and local control where it makes sense.
SONiC is evolving toward being AI-native: tighter telemetry, richer APIs, SmartNIC integration, and offload models are all accelerating its suitability for large AI fabrics. Standards work (e.g., Ultra Ethernet Consortium collaborations with OCP) further smooth hardware compatibility, helping organizations adopt high-performance Ethernet for AI without sacrificing vendor choice.
That said, Community SONiC is powerful but raw. Community builds need hardening, rigorous QA, and lifecycle management to be safe for mission-critical AI workloads, which is where specialized partners matter.
Partnering for success in the AI-native era
If you’re thinking “we want SONiC, but we don’t have the in-house expertise, QA, or engineering hours to ship safely”, that’s the gap companies like PLVision fill.
PLVision blends deep switch-software engineering with active community leadership: we build hardened SONiC images, port to networking hardware, and deliver product-grade distributions. In plain terms: we take open networking from prototype to predictable production, while keeping your stack vendor-neutral and future-ready.
Our offerings include:
- Custom product development based on open-source technologies, SONiC-based product development services for Telco use cases, and SwitchDev development.
- Open NOS enablement and customization for hardware, encompassing SONiC-DASH API implementation, porting Community SONiC to your hardware, offloading xPU/SmartNIC customization and support.
- Network infrastructure transition to open NOS, such as SONiC adoption for enterprise networks and generating Community SONiC hardened images for data centers.
- SONiC Lite, PLVision’s enterprise distribution of Community SONiC, designed for cost-effective management and access platforms. It’s ideal for less demanding networking equipment in data center, campus, and edge deployments.
By owning your SONiC distribution, you gain full control, eliminate vendor lock-in and licensing fees, and align your infrastructure with AI’s demands.
Final thought: design for the loop, not the snapshot
AI and networking are co-evolving. Design infrastructure with telemetry and automation as first-class citizens, embrace open standards to avoid vendor lock-in, and invest in the software and operational practices that make automation trustworthy.
When you understand how AI enhances networking (automation, predictive assurance) and how networking fuels AI (scalable, lossless fabrics, telemetry, programmability), you can build infrastructures ready for tomorrow’s challenges. If you’re exploring open networking for your business, working with experienced partners can shorten the path from promising proof-of-concept to dependable production. What’s your next move?
Contact Us to Discuss Your Use Case



